
Text Adventure Benchmarks Revisited
Spoiler Alert: They Still Suck

In April, I wrote about a custom text adventure benchmark (ala Zork) I created for AI agents (LLM + scaffold).
To refresh, here is the first part of the domain description from that post:
Hand-crafted dungeon comprised of 10 connected rooms, 8 takeable objects, and 11 fixed but interactable/informational objects.
The first central puzzle is spatial/navigational. The player must find a handle in one room that fits into a crank in another room, and rotate it to rotate a centrally-located rotating room that only has two openings in cardinal directions. The openings in the rotating room must align with doorways in adjacent rooms to allow movement between them. In the crank room there is a diagram of the rotating room that updates when the crank is turned and indicates open passages with green or red markers at N/W/S/E on the circle.

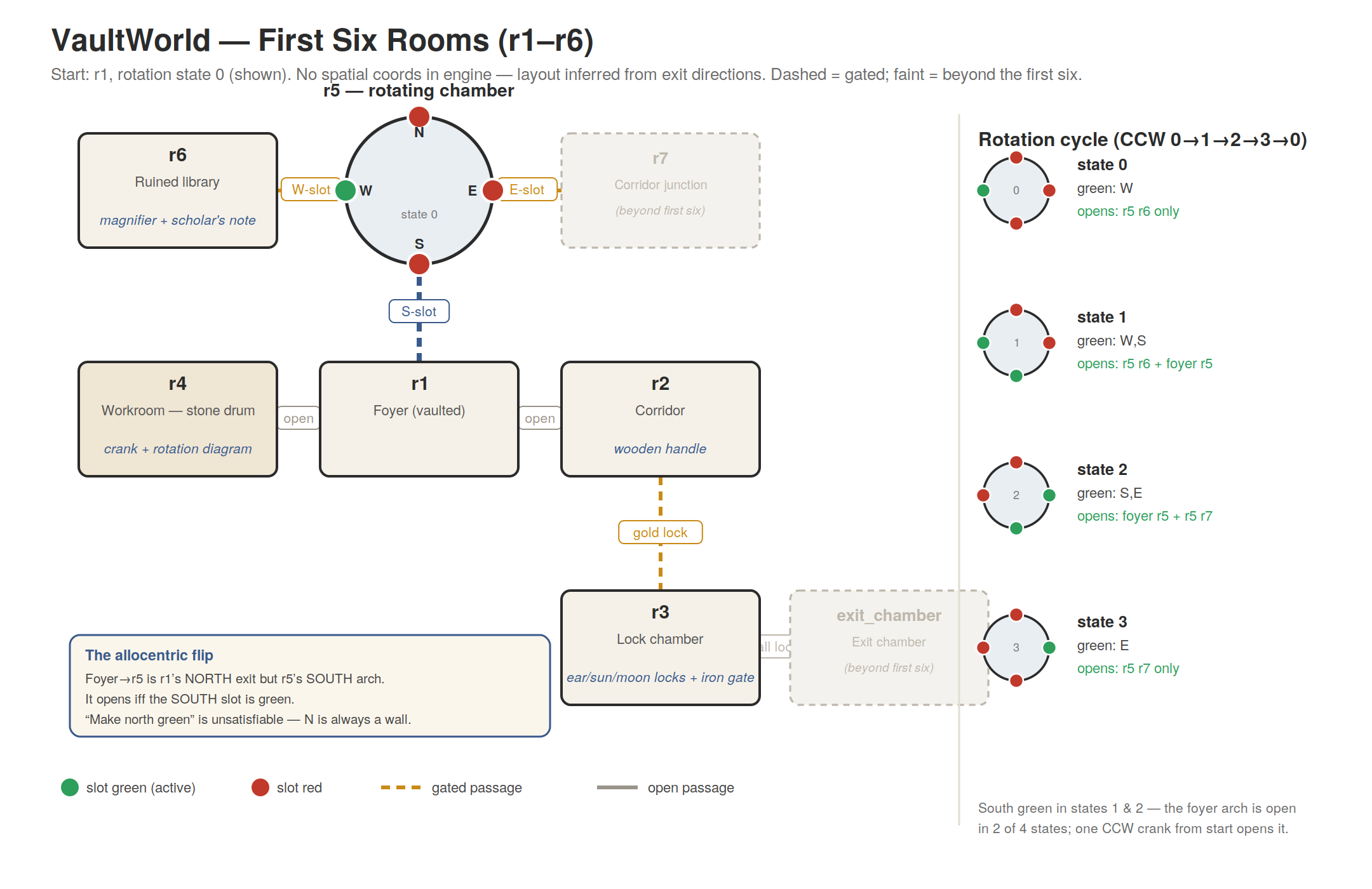
I have made significant changes to the scaffolding based on various papers I’ve read. And I’ve tested up to Claude Opus 4.8. I was going to test with Fable, but you can probably guess what happened there.
The agents all struggle terribly with the initial central puzzle, which probably is the hardest in the entire domain. They fail in a number of different ways, depending on the trial:
They have a locality bias, so they often confuse the information diagram on the wall with the target of the puzzle itself.
Again, because of the locality bias, they often think the mechanism is altering the exit topology in the crank room itself, rather than in the rotating room.
When they do make the connection between the crank and the rotating room, they almost never understand that what’s being aligned are the openings with the adjacent exits. When S is green on the diagram, that means the slot on the rotating room has aligned with the doorway in the room to its south. The agents almost always think it should be opening a doorway south from a room it is in, instead of one it’s trying to get to.
They struggle with the basic notion of trial combined with exploration, a necessary behavior in these types of games. Fiddle with a mechanism in one place, then travel around to see what, if anything, changed. And when they do find that something has changed, binding the previous action with the effect is very difficult for them.
If we’re ever going to get artificial scientists, these modes of reasoning will need to be mastered. Right now they can’t even handle what is essentially a toy domain. They need to be able to:
Observe the state of the world
Generate hypotheses based on the state of the world
Take actions that will generate evidence towards confirm or disconfirming one or more hypotheses
Update those hypotheses based on whatever evidence they find
Rinse and repeat
The latest version of my scaffolding does exactly this. It enforces hypothesis generation and updating, a prediction step prior to acting to try to evaluate what the best actions would be to take in order to generate good evidence, the action step, observing any changes, and updating hypotheses. The scaffolding also includes an updatable map that is persisted and read in at every step, and a checkable inventory.
All that enforced framework essentially puts it on rails to think and act like a text adventure solver and more generically like a scientist. But recent models all fail. Or rather, they fail to actually make the correct inferences required to understand the puzzle. Sometimes they actually make it through the rotating room by sheer luck.
Fable is supposed to be better at spatial reasoning. Supposedly, representatives from Anthropic went to the White House today to negotiate redeployment of the model to the public. I guess we’ll see what happens this week.
Another wrinkle I tried, to jostle the agent out of its egocentric frame, under the hypothesis that that was largely responsible for the locality bias, was to try to have the model consider the world state and its own actions from a more third-person omniscient pov. That didn’t really help either.
One by one, the gaps that I though were impeding its ability to perform well in this domain were sealed with additional pieces of scaffolding. I gave it a detailed memory, a helpful framework for thinking and acting the way it needed to, a map utility, and so on. Nothing really helped.
The models, even when embedded in a powerful, tailor-made scaffold, perform poorly at associating non-local and non-sequential causes with effects. In other words, when you fiddle with something, and it affects something in another place and/or time, humans can bind that relationship relatively easily. So far, with many interventions, I cannot get any model to reliably do that.
This might be a function of the tight training feedback loop for predicting the very next token (though I know there’s research showing internal representations of thinking ahead to form rhyming lines in poetry). But there are lots of examples of that kind of thing for poetry in the training data. It’s entirely possible that step-by-step procedural knowledge of non-local causal problem solving is largely absent from the training data. We might need to generate it explicitly for training. I don’t know.
What I do know is that for now I’ve reached what I think is the limit of capacity for this domain, but I think it remains a useful benchmark in an environment of increasingly saturated benchmarks.